6 Student’s t-test
For this test we assume that both sample data sets are normally distributed and have equal variance. We test to see if the means of the two samples differ significantly from each other.
The language used in this section is slightly different to that used in section 3.1. Although the language used in section 3.1 was technically more correct, the sentences are somewhat more onerous to read. Here I’ve opted for an easier reading style at the expense of technical accuracy. Please feel free to re-write this section (at your own leisure).
6.1 Section commands
New commands used in this section:
| Function | Description |
|---|---|
get_summary_stats() |
Computes summary statistics |
bartlett.test() |
Perform Bartlett’s test for equality of variance (normally distributed data) |
levene_test() |
Perform Levene’s test for equality of variance (non-normally distributed data) |
6.2 Data and hypotheses
For example, suppose we now measure the body lengths of male guppies (in mm) collected from two rivers in Trinidad; the Aripo and the Guanapo. We want to test whether the mean body length differs between samples. We form the following null and alternative hypotheses:
- \(H_0\): The mean body length does not differ between the two groups \((\mu A = \mu G)\)
- \(H_1\): The mean body length does differ between the two groups \((\mu A \neq \mu G)\)
We use a two-sample, two-tailed t-test to see if we can reject the null hypothesis.
- We use a two-sample test because we now have two samples.
- We use a two-tailed t-test because we want to know if our data suggest that the true (population) means are different from one another rather than that one mean is specifically bigger or smaller than the other.
- We’re using Student’s t-test because the sample sizes are big and because we’re assuming that the parent populations have equal variance (We can check this later).
The data are stored in the file data/tidy/CS1-twosample.csv.
Read this into R:
rivers <- read_csv("data/tidy/CS1-twosample.csv")6.3 Summarise and visualise
Let’s summarise the data…
# get common summary stats for the length column
rivers %>%
select(-id) %>%
group_by(river) %>%
get_summary_stats(type = "common")## # A tibble: 2 × 11
## river variable n min max median iqr mean sd se ci
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Aripo length 39 17.5 26.4 20.1 2.2 20.3 1.78 0.285 0.577
## 2 Guanapo length 29 11.2 23.3 18.8 2.2 18.3 2.58 0.48 0.983and visualise it:
rivers %>%
ggplot(aes(x = river, y = length)) +
geom_boxplot()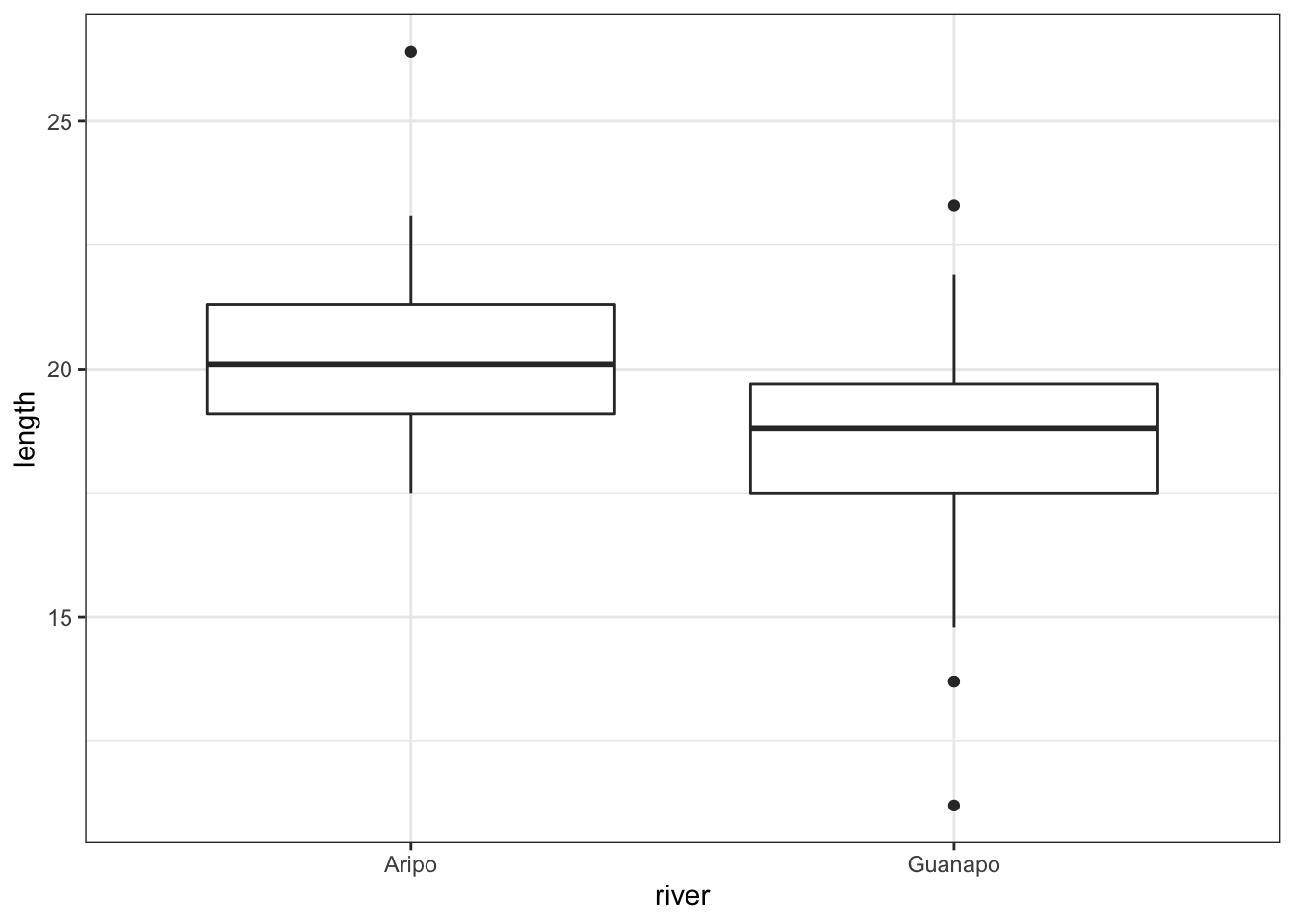
The boxplot does appear to suggest that the two samples have different means, and moreover that the guppies in Guanapo may be smaller than the guppies in Aripo. It isn’t immediately obvious that the two populations don’t have equal variances though, so we plough on.
6.4 Assumptions
In order to use a Student’s t-test (and for the results to be strictly valid) we have to make three assumptions:
- The parent distributions from which the samples are taken are both normally distributed (which would lead to the sample data being normally distributed too).
- Each data point in the samples is independent of the others.
- The parent distributions should have the same variance.
In this example the first assumption can be ignored as the sample sizes are large enough (because of maths, with Aripo containing 39 and Guanapo 29 samples). If the samples were smaller then we would use the tests from the previous section.
The second point we can do nothing about unless we know how the data were collected, so again we ignore it.
The third point regarding equality of variance can be tested using either Bartlett’s test (if the samples are normally distributed) or Levene’s test (if the samples are not normally distributed). This is where it gets a bit trickier. Although we don’t care if the samples are normally distributed for the t-test to be valid (because the sample size is big enough to compensate), we do need to know if they are normally distributed in order to decide which variance test to use.
So we perform a Shapiro-Wilk test on both samples separately.
# group data by river and perform test
rivers %>%
group_by(river) %>%
shapiro_test(length)## # A tibble: 2 × 4
## river variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 Aripo length 0.936 0.0280
## 2 Guanapo length 0.949 0.176We can see that whilst the Guanapo data is probably normally distributed (p = 0.1764 > 0.05), the Aripo data is unlikely to be normally distributed (p = 0.02802 < 0.05). Remember that the p-value gives the probability of observing each sample if the parent population is actually normally distributed.
The Shapiro-Wilk test is quite sensitive to sample size. This means that if you have a large sample then even small deviations from normality will cause the sample to fail the test, whereas smaller samples are allowed to pass with much larger deviations. Here the Aripo data has nearly 40 points in it compared with the Guanapo data and so it is much easier for the Aripo sample to fail compared with the Guanapo data.
6.5 Exercise: Q-Q plots rivers
Exercise 6.1 Q-Q plots for rivers data
Create the Q-Q plots for the two samples and discuss with your neighbour what you see in light of the results from the above Shapiro-Wilk test.
Answer
To create the Q-Q plots we need to filter out the relevant data first. If we want to use the lm() function in pipes, we still need to tell it where the data is coming from. Long story short: because the data = argument is not at the beginning we need to add a . (dot):
# filter out the Guanapo data
# and define the model
lm_guanapo <- rivers %>%
filter(river == "Guanapo") %>%
lm(length ~ 1, data = .)
# filter out the Aripo data
# and define the model
lm_aripo <- rivers %>%
filter(river == "Aripo") %>%
lm(length ~ 1, data = .)
# Q-Q plot Guanapo
lm_guanapo %>%
resid_panel(plots = "qq")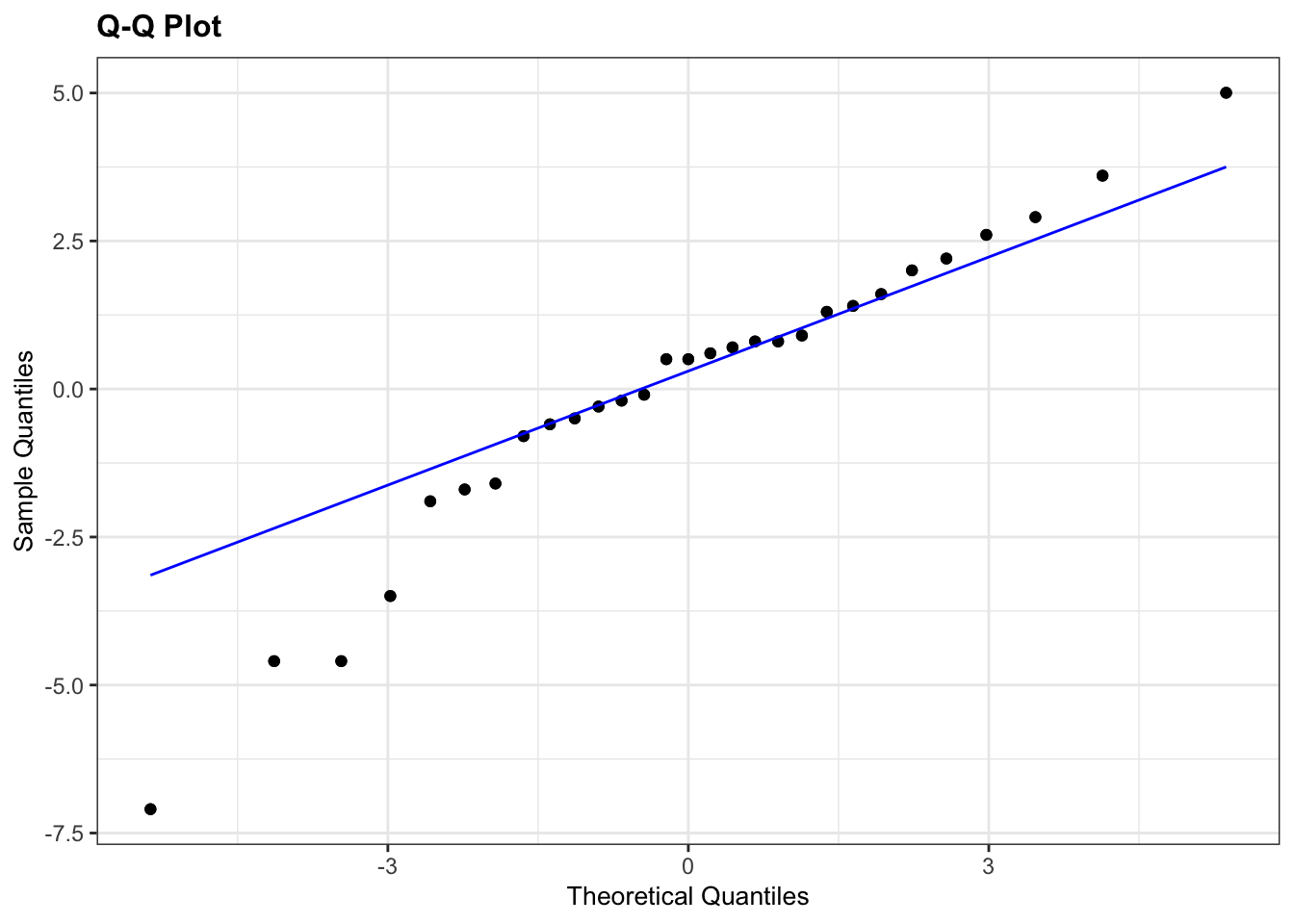
# Q-Q plot Aripo
lm_aripo %>%
resid_panel(plots = "qq")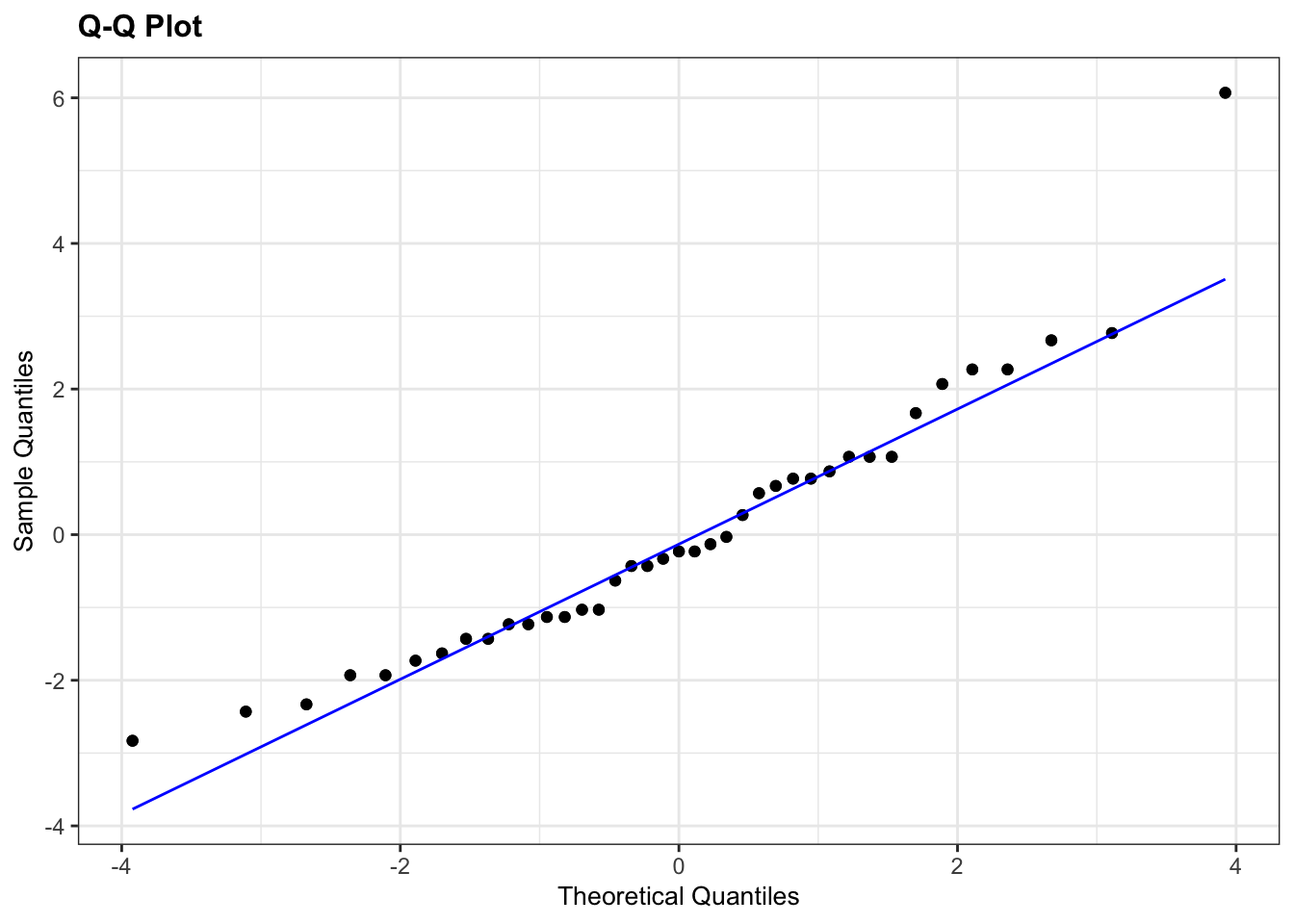
The Q-Q plots highlight the issue with the Shapiro-Wilk tests: the data for Aripo look pretty normally distributed, whereas the Shapiro-Wilk test suggested that they are not. This is because it’s easy for the test to fail when there is sufficient data. Based on the Q-Q plot I would argue that the assumption of normality for the Guanapo data is less certain than for Aripo, whereas the Shapiro-Wilk test tells us they are likely to be normally distributed.
What to do? Well, I would rely more on the graphical interpretation that the output of the Shapiro-Wilk test. There is only one data point in the Aripo data set that deviates from the line, but there is no clear snaking around the line. For the Guanapo data there is some drifting away from the Q-Q line at the bottom but no clear snaking. There are a reasonable number of data points too, so I’d be happy to argue that the data are normal enough for me to perform a t-test.
6.6 Equality of variance
Remember that statistical tests do not provide answers, they merely suggest patterns. Human interpretation is still a crucial aspect to what we do.
The Shapiro-Wilk test has shown that the data are not normal enough and so in order to test for equality of variance we will use Levene’s test.
rivers %>%
levene_test(length ~ river)## # A tibble: 1 × 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 1 66 1.77 0.188The key bit of information is the p column. This is the p-value (0.1876) for this test. And this tells us the probability of observing these two samples if they come from distributions with the same variance. As this probability is greater than our arbitrary significance level of 0.05 then we can be somewhat confident that the necessary assumptions for carrying out Student’s t-test on these two samples was valid. (Once again woohoo!)
6.6.1 Bartlett’s test
If we had wanted to carry out Bartlett’s test (i.e. if the data had been sufficiently normally distributed) then the command would have been:
bartlett.test(length ~ river, data = rivers)##
## Bartlett test of homogeneity of variances
##
## data: length by river
## Bartlett's K-squared = 4.4734, df = 1, p-value = 0.03443The relevant p-value is given on the 3rd line.
Here we use bartlett.test() from base R. Surprisingly, the rstatix package does not have a built-in equivalent.
If we wanted to get the output of the Bartlett test into a tidy format, we could do the following, where we take the rivers data set and pipe it to the bartlett.test() function. Note that we need to define the data using a dot (.), because the first input into bartlett.test() is not the data. We then pipe the output to the tidy() function, which is part of the broom library, which kindly converts the output into a tidy format. Handy!
# load the broom package
library(broom)
# perform Bartlett's test on the data and tidy
rivers %>%
bartlett.test(length ~ river,
data = .) %>%
tidy()## # A tibble: 1 × 4
## statistic p.value parameter method
## <dbl> <dbl> <dbl> <chr>
## 1 4.47 0.0344 1 Bartlett test of homogeneity of variances6.7 Implement test
In this case we’re ignoring the fact that the data are not normal enough, according to the Shapiro-Wilk test. However, because the sample sizes are pretty large and the t-test is also pretty robust in this case, we can perform a t-test. Remember, this is only allowed because the variances of the two groups (Aripo and Guanapo) are equal.
Perform a two-sample, two-tailed, t-test:
# two-sample, two-tailed t-test
rivers %>%
t_test(length ~ river,
alternative = "two.sided",
var.equal = TRUE)Here we do the following:
- We take the data set and pipe it to the
t_test()function - The
t_test()function takes the formula in the formatvariable ~ category - Again the alternative is
two.sidedbecause we have no prior knowledge about whether the alternative should begreaterorless - The last argument says whether the variance of the two samples can be assumed to be equal (Student’s t-test) or unequal (Welch’s t-test)
6.8 Interpret output and report results
Let’s look at the results of the t-test that we performed on the original (stacked) data frame:
## # A tibble: 1 × 8
## .y. group1 group2 n1 n2 statistic df p
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 length Aripo Guanapo 39 29 3.84 66 0.000275- The first 5 columns give you information on the variable (
.y.), groups and sample size of each group - The
statisticcolumn gives the t-value of 3.8433 (we need this for reporting) - The
dfcolumn tell us there are 66 degrees of freedom (we need this for reporting) - The
pcolumn gives us a p-value of 0.0002754
Again, the p-value is what we’re most interested in. Since the p-value is very small (much smaller than the standard significance level) we choose to say “that it is very unlikely that these two samples came from the same parent distribution and as such we can reject our null hypothesis” and state that:
A Student’s t-test indicated that the mean body length of male guppies in the Guanapo river (18.29 mm) differs significantly from the mean body length of male guppies in the Aripo river (20.33 mm) (t = 3.8433, df = 66, p = 0.0003).
Now there’s a conversation starter.
6.9 Exercise: Turtles
Exercise 6.2 Serum cholesterol concentrations in turtles
Using the following data, test the null hypothesis that male and female turtles have the same mean serum cholesterol concentrations.
| Male | Female |
|---|---|
| 220.1 | 223.4 |
| 218.6 | 221.5 |
| 229.6 | 230.2 |
| 228.8 | 224.3 |
| 222.0 | 223.8 |
| 224.1 | 230.8 |
| 226.5 | NA |
- Create a tidy data frame and save as a
.csvfile - Write down the null and alternative hypotheses
- Import the data into R
- Summarise and visualise the data
- Check your assumptions (normality and variance) using appropriate tests and plots
- Perform a two-sample t-test
- Write down a sentence that summarises the results that you have found
Answer
6.9.1 Data
Here the data is in a tidy format, with each variable in its own column, each row an observation (and a unique identifier for each observation).
6.9.3 Load, summarise and visualise data
I’d always recommend storing data in tidy, stacked format (in fact I can’t think of any situation where I would want to store data in an untidy, unstacked format!) So for this example I manually input the data into Excel in the following layout, saving the data as a CSV file and reading it in:
# load the data
turtle <- read_csv("data/tidy/CS1-turtle.csv")
# and have a look
turtle## # A tibble: 13 × 3
## id serum sex
## <dbl> <dbl> <chr>
## 1 1 220. Male
## 2 2 219. Male
## 3 3 230. Male
## 4 4 229. Male
## 5 5 222 Male
## 6 6 224. Male
## 7 7 226. Male
## 8 8 223. Female
## 9 9 222. Female
## 10 10 230. Female
## 11 11 224. Female
## 12 12 224. Female
## 13 13 231. FemaleLet’s summarise the data (although a visualisation is probably much easier to work with):
# create summary statistics for each group
turtle %>%
select(-id) %>%
group_by(sex) %>%
get_summary_stats(type = "common")## # A tibble: 2 × 11
## sex variable n min max median iqr mean sd se ci
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Female serum 6 222. 231. 224. 5.22 226. 3.87 1.58 4.06
## 2 Male serum 7 219. 230. 224. 6.6 224. 4.26 1.61 3.94and visualise the data:
# visualise the data
turtle %>%
ggplot(aes(x = sex, y = serum)) +
geom_boxplot()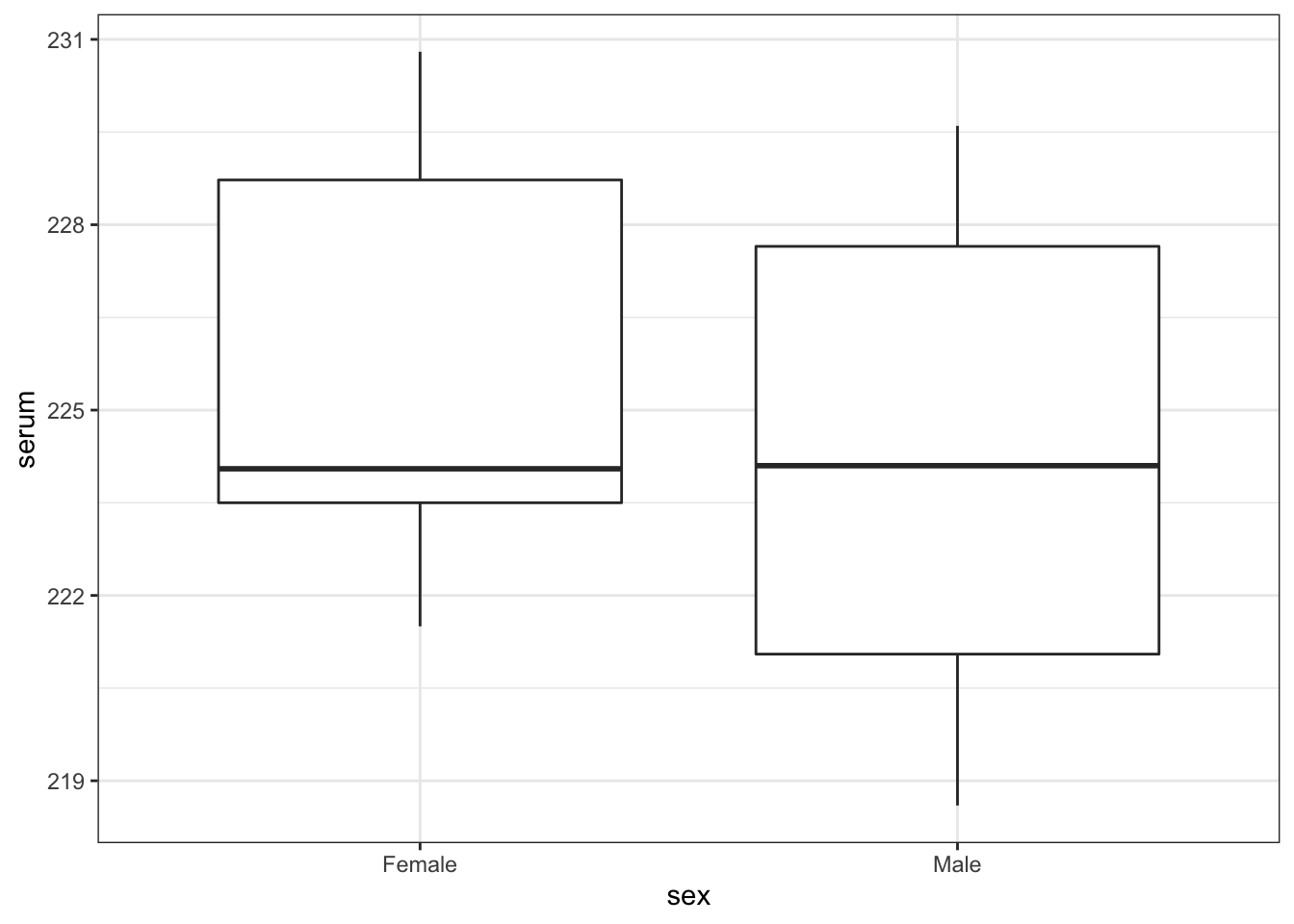
As always we use the plot and summary to assess three things:
- Does it look like we’ve loaded the data in correctly?
- We have two groups and the extreme values of our plots seem to match with our dataset, so I’m happy that we haven’t done anything massively wrong here.
- Do we think that there is a difference between the two groups?
- We need the result of the formal test to make sense given the data, so it’s important to develop a sense of what we think is going to happen here. Whilst the ranges of the two groups suggests that the Female serum levels might be higher than the males when we look at things more closely we realise that isn’t the case. The boxplot shows that the median values of the two groups is virtually identical and this is backed up by the summary statistics we calculated: the medians are both about 224.1, and the means are fairly close too (225.7 vs 224.2). Based on this, and the fact that there are only 13 observations in total I would be very surprised if any test came back showing that there was a difference between the groups.
- What do we think about assumptions?
- Normality looks a bit worrying: whilst the
Malegroup appears nice and symmetric (and so might be normal), theFemalegroup appears to be quite skewed (since the median is much closer to the bottom than the top). We’ll have to look carefully at the more formal checks to decided whether we think the data are normal enough for us to use a t-test. - Homogeneity of variance. At this stage the spread of the data within each group looks similar, but because of the potential skew in the Female group we’ll again want to check the assumptions carefully.
- Normality looks a bit worrying: whilst the
6.9.4 Assumptions
Normality
Let’s look at the normality of each of the groups separately. There are several ways of getting at the serum values for Males and Females separately. We’ll use the unstacking method, then use Shapiro-Wilk followed by qqplots.
# perform Shapiro-Wilk test on each group
turtle %>%
group_by(sex) %>%
shapiro_test(serum)## # A tibble: 2 × 4
## sex variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 Female serum 0.842 0.135
## 2 Male serum 0.944 0.674The p-values for both Shapiro-Wilk tests are non-significant which suggests that the data are normal enough. This is a bit surprising given what we saw in the boxplot but there are two bits of information that we can use to reassure us.
- The p-value for the Female group is smaller than for the Male group (suggesting that the Female group is closer to being non-normal than the Male group) which makes sense.
- The Shapiro-Wilk test is generally quite relaxed about normality for small sample sizes (and notoriously strict for very large sample sizes). For a group with only 6 data points in it, the data would actually have to have a really, really skewed distribution. Given that the Female group only has 6 data points in it, it’s not too surprising that the Shapiro-Wilk test came back saying everything is OK.
# create Q-Q plots for both groups
# Females
lm_turtle_females <- turtle %>%
filter(sex == "Female") %>%
lm(serum ~ 1, data = .)
# Males
lm_turtle_males <- turtle %>%
filter(sex == "Male") %>%
lm(serum ~ 1, data = .)
# Q-Q plot Females
lm_turtle_females %>%
resid_panel(plots = "qq")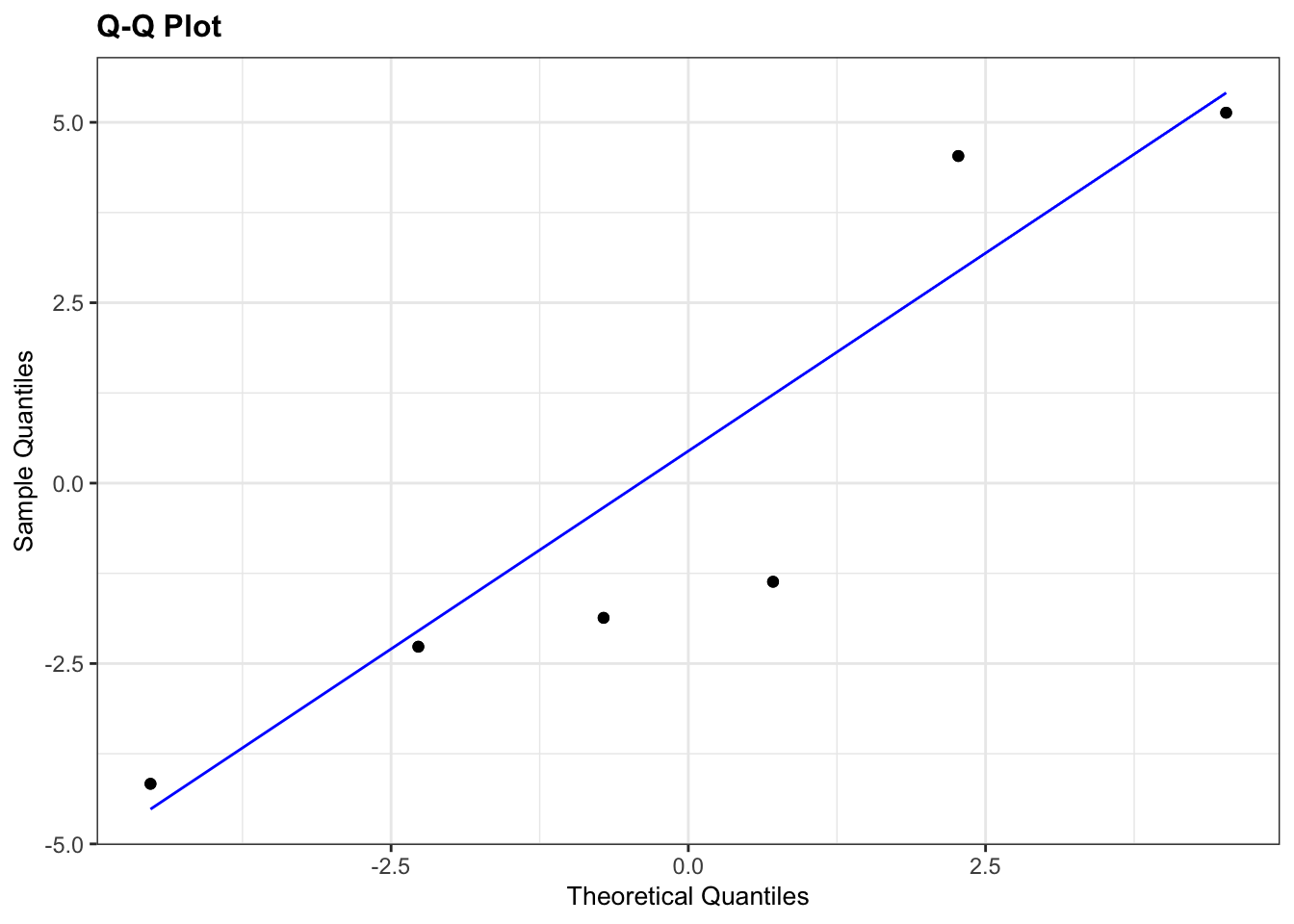
# Q-Q plot Males
lm_turtle_males %>%
resid_panel(plots = "qq")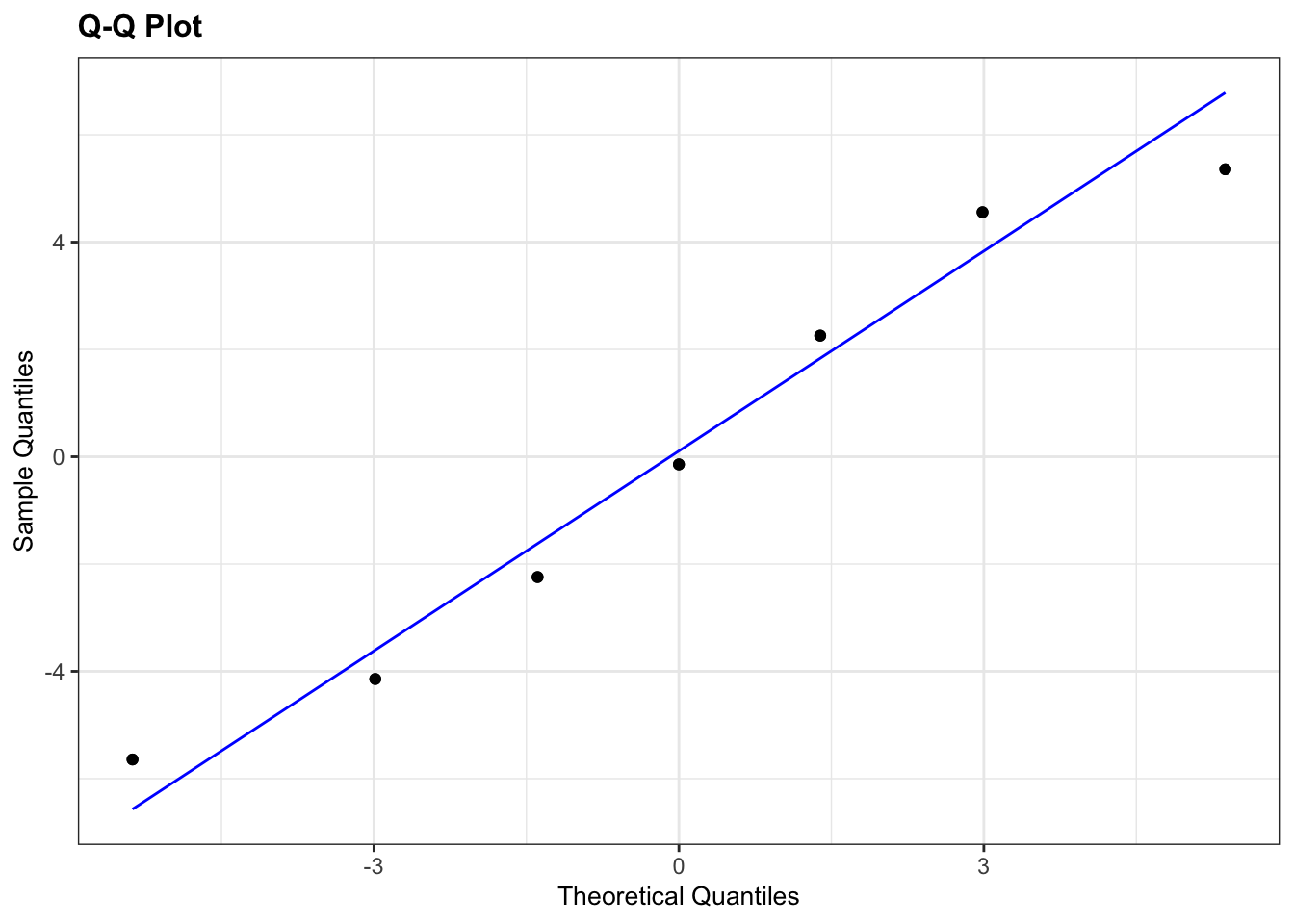
The results from the Q-Q plots echo what we’ve already seen from the Shapiro-Wilk analyses. The Male group doesn’t look too bad whereas the Female group looks somewhat dodgy.
Overall, the assumption of normality of the data doesn’t appear to be very well met at all, but we do have to bear in mind that there are only a few data points in each group and we might just be seeing this pattern in the data due to random chance rather than because the underlying populations are actually not normally distributed. Personally, though I’d edge towards non-normal here.
Homogeneity of Variance
It’s not clear whether the data are normal or not, so it isn’t clear which test to use here. The sensible approach is to do both and hope that they agree (fingers crossed!)
Bartlett’s test gives us:
# perform Bartlett's test
bartlett.test(serum ~ sex,
data = turtle)##
## Bartlett test of homogeneity of variances
##
## data: serum by sex
## Bartlett's K-squared = 0.045377, df = 1, p-value = 0.8313and Levene’s test gives us:
# perform Levene's test
turtle %>%
levene_test(serum ~ sex)## # A tibble: 1 × 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 1 11 0.243 0.631The good news is that both Levene and Bartlett agree that there is homogeneity of variance between the two groups (thank goodness!).
Overall, what this means is that we’re not too sure about normality, but that homogeneity of variance is pretty good.
6.9.5 Implement two-sample t-test
Because of the result of the Bartlett test I know that I can carry out a two-sample Student’s t-test (as opposed to a two-sample Welch’s t-test, if you’re confused, see Figure 3.2)
# perform two-sample t-test
turtle %>%
t_test(serum ~ sex,
alternative = "two.sided",
var.equal = TRUE)## # A tibble: 1 × 8
## .y. group1 group2 n1 n2 statistic df p
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 serum Female Male 6 7 0.627 11 0.544With a p-value of 0.544, this test tells me that there is insufficient evidence to suggest that the means of the two groups are different. A suitable summary sentence would be:
A Student’s two-sample t-test indicated that the mean serum cholesterol level did not differ significantly between Male and Female turtles (t = 0.627, df = 11, p = 0.544).
6.9.6 Discussion
In reality, because of the ambiguous normality assumption assessment, for this dataset I would actually carry out two different tests; the two-sample t-test with equal variance and the Mann-Whitney U test. If both of them agreed then it wouldn’t matter too much which one I reported (I’d personally report both with a short sentence to say that I’m doing that because it wasn’t clear whether the assumption of normality had or had not been met), but it would be acceptable to report just one.